0 目录
- 2.1 MIPS汇编语言的风格初探
- 2.2 寄存器
- 2.3 整数乘法硬件单元
- 2.4 加载与存储:寻址方式
- 2.5 存储器与寄存器的数据类型
- 2.6 汇编语言的合成指令
- 2.7 基本地址空间
- 2.8 流水线可见性
架构这个词,英文是architecture,牛津词典对其解释为the design and structure of a computer system。所以,这个词体现的是设计和结构,也就是说,是一个抽象机器或通用模型概念上的描述,而不是一个真实机器的实现。这就好比一辆手动挡车,无论是前轮驱动还是后轮驱动,它的油门总是在右,离合器在左。这里,油门和离合器的位置就相当于架构,前轮还是后轮驱动是具体实现。所以,相同的架构,实现未必相同。
当然了,如果你是一个拉力赛车手,在湿滑的路上高速行驶时,前轮驱动还是后轮驱动就很重要了。计算机也是一样,如果对某个方面有特殊的需求,实现的细节就很重要了。
通常,CPU架构由指令集和寄存器组成。术语-指令集和架构在语义上非常接近,所以,有时候你也会见到这两个词的组合缩写-指令集架构(ISA)。
对于MIPS指令集架构描述最好的,肯定是MIPS公司出版的MIPS32和MIPS64架构规范。MIPS32是MIPS64的一个子集,用于描述具有32位通用目的寄存器的CPU。为了简单,我们缩写为MIPS32/64。
生产MIPS架构CPU的公司,尽量兼容MIPS32/64规范。
在MIPS32/64规范之前,已经发布了多版的MIPS架构。但是,这些旧架构只是规定了软件使用的指令和资源,并没有定义操作系统所需要的CPU控制机制,而是将其认为应该在实现时定义。通俗地讲,早期版本的MIPS架构对CPU控制单元的硬件实现不做约束,由芯片制造商在实现时自己实现。这意味着,对于可移植操作系统需要做更多的工作,去适配因此而带来的差异。好消息是,几乎每一个版本的MIPS架构,都有一个作为所有实现的父版本存在。
-
MIPS I:
最早的32位处理器(R2000/3000)使用的指令集,几乎每一个MIPS架构CPU都可以运行这些指令。
-
MIPS II:
为没有投产的MIPS-R6000机器定义的指令集。MIPS-II是MIPS32的前身。
-
MIPS III:
为R4000引入的64位指令集。
-
MIPS IV:
在MIPS-III基础上添加了浮点指令,R10000和R5000硬件实现中使用。
-
MIPS V:
添加了2个奇怪的SIMD浮点操作指令,但是没有具体的CPU实现。大多是作为MIPS64架构的可选部分-
单精度对(paired-single)-出现。 -
MIPS32、MIPS64:
1998年,由从
Silicon Graphics公司分拆出来的MIPS Technologies Inc.公司制定的标准。该标准第一次纳入了CPU控制的功能,由协处理器0实现。MIPS32是MIPS-II的超集,MIPS64是MIPS-IV的超集(还以可选的方式包含了MIPS-V的大部分)。大多数1999年之后设计的MIPS架构CPU都兼容这些标准。所以,在后面的描述中,我们使用
MIPS32/64作为基础架构。到目前为止,MIPS32/64规范已经发布到了第6版。
指令集扩展的规范化—ASE
我们一直强调,RISC和保持指令集小没有关系。事实上,RISC的简单性,更容易让人进行扩展。
随着MIPS架构的CPU出现在嵌入式系统中,许多新的指令如雨后春笋般地冒出来。MIPS32/64吸收了一些,同时也提供了一种扩展机制ASE(Application-Specific instruction set Extensions)。ASE作为MIPS32/64的扩展存在,可以通过配置寄存器进行选择。下面是一些选项:
-
MIPS16e:
类似于ARM架构的thumb指令的一种扩展。是一种旧扩展。基本不用。
-
MDMX:
类似于英特尔的MMX扩展的早期版本。但是,MDMX从来没有实现。
-
SmartMIPS:
为提高MIPS架构的加密性能而扩展的一个模块。这个功能扩展还是比较有用的,尤其是在当下这个特别注重数据安全的时代。
-
MT:
将硬件多线程技术添加到MIPS核中。2005年,第一次出现在MIPS公司的34-K系列产品中。
-
DSP:
音视频处理指令,将饱和和SIMD算法运用到小整数上。看上去比MDMX更有用。2005年,开始在MIPS公司的24-K和34-K系列中推出。
MIPS32/64规范还有一些可选项,它们不能被看作为指令集的扩展:
-
浮点单元:
协处理器1控制。
-
CP2:
协处理器2,用户自定义。很少有人使用。
-
CorExtend:
用户自定义指令集。2002/2003年大肆炒作的一个概念,ARM和Tensilica公司也宣布支持。
-
EJTAG:
调试工具。
-
单精度对:
浮点单元的扩展,提供SIMD操作。每条指令可以同时操作2个单精度值。
-
MIPS-3D:
通常和单精度对结合使用,提供了一些指令,用于3D场景渲染时的浮点矩阵运算。
2.1 MIPS汇编语言的风格初探
本部分对汇编语言只做一个简单的介绍,详细的理解后面会再展开。
我们或多或少地已经接触过汇编语言,下面是MIPS架构的一小段汇编代码:
# 注释
entrypoint: # 标签
addu $1, $2, $3 # 基于寄存器的加法,等价于 $1 = $2 + $3
跟大部分的汇编语言一样,基于行的分割语言。原生注释符号是#,编译器会忽略掉#后面的所有文本。但是可以在一行中插入多条语句,使用;进行分割。
标签(label)使用:开始,可以包含各类符号。标签可以定义代码的入口点和数据存储的开始位置。
MIPS汇编程序可以使用数字标记的通用寄存器,也可以使用C语言的预处理器和一些标准头文件,这样就可以使用寄存器的别称(关于别称请参考下一节)。当然了,如果使用C预处理器,注释也可以使用C风格。
大多数指令是三目运算指令,目的寄存器在左边(与X86相反)。
subu $1, $2, $3
代表的表达式是:
$1 = $2 - $3;
目前,了解这些就足够了。
2.2 寄存器
MIPS有32个通用寄存器($0-$31),各寄存器的功能及汇编程序中使用约定如下:
下表描述32个通用寄存器的别名和用途
| 寄存器 | 别名 | 使用 |
|---|---|---|
| $0 | $zero | 常量0 |
| $1 | $at | 保留给汇编器 |
| $2-$3 | $v0-$v1 | 函数返回值 |
| $4-$7 | $a0-$a3 | 函数调用参数 |
| $8-$15 | $t0-$t7 | 临时寄存器 |
| $16-$23 | $s0-$s7 | 保存寄存器 |
| $24-$25 | $t8-$t9 | 临时寄存器 |
| $26-$27 | $k0-$k1 | 保留给系统 |
| $28 | $gp | 全局指针 |
| $29 | $sp | 堆栈指针 |
| $30 | $fp | 帧指针 |
| $31 | $ra | 返回地址 |
##详细的寄存器使用说明
-
$0:即$zero,该寄存器总是返回零,为0这个有用常数提供了一个简洁的编码形式。
比如,下面的代码:
move $t0,$t1(伪指令常用)实际为:
add $t0,$0,$t1使用伪指令可以简化任务,汇编程序提供了比硬件更丰富的指令集。
-
$1:即$at,该寄存器为汇编保留。
由于I型指令的立即数字段只有16位,在加载大常数时,编译器或汇编程序需要 把大常数拆开,然后重新组合到寄存器里。比如加载一个32位立即数需要 lui(装入高位立即数)和addi两条 指令。像MIPS程序拆散和重装大常数由汇编程序来完成,汇编程序必需一个临时寄存器来重组大常数,这也是为汇编 保留$at的原因之一。
-
$2..$3:($v0-$v1)用于子程序的非浮点结果或返回值。
对于子程序如何传递参数及如何返回,MIPS范围有一套约 定,堆栈中少数几个位置处的内容装入CPU寄存器,其相应内存位置保留未做定义,当这两个寄存器不够存 放返回值时,编译器通过内存来完成。
-
$4..$7:($a0-$a3)用来传递前四个参数给子程序,不够的用堆栈。
a0-a3和v0-v1以及ra一起来支持子程序/过程调用,分别用以传递参数,返回结果和存放返回地址。当需要使用更多的寄存器时,就需要堆栈了,MIPS编译器总是为参数在堆栈中留有空间以防有参数需要存储。
-
$8..$15:($t0-$t7)临时寄存器,子程序可以使用它们而不用保留。
-
$16..$23:($s0-$s7)保存寄存器,在过程调用过程中需要保留(被调用者保存和恢复,还包括$fp和$ra)。
MIPS提供了临时寄存器和保存寄存器,这样就减少了寄存器溢出(spilling,即将不常用的变量放到存储器的过程), 编译器在编译一个叶(leaf)过程(不调用其它过程的过程)的时候,总是在临时寄存器分配完了才使用需要 保存的寄存器。
-
$24..$25:($t8-$t9)同($t0-$t7)
-
$26..$27:($k0,$k1)为操作系统/异常处理保留,至少要预留一个。
异常(或中断)是一种不需要在程序中显示调用的过程。MIPS有个叫异常程序计数器(exception program counter,EPC)的寄存器,属于CP0寄存器,用于保存造成异常的那条指令的地址。查看控制寄存器的唯一方法是把它复制到通用寄存器里,指令mfc0 (move from system control)可以将EPC中的地址复制到某个通用寄存器中,通过跳转语句(jr),程序可以返 回到造成异常的那条指令处继续执行。MIPS程序员都必须保留两个寄存器$k0和$k1,供操作系统使用。
发生异常时,这两个寄存器的值不会被恢复,编译器也不使用k0和k1,异常处理函数可以将返回地址放到这两个中的任何一个,然后使用jr跳转到造成异常的指令处继续执行。
-
$28:($gp)为了简化静态数据的访问,MIPS软件保留了一个寄存器:全局指针gp(global pointer,$gp)。
全局指针只存储静态数据区中的运行时决定的地址,在存取位于gp值上下32KB范围内的数据时,只需要一条以gp为基指针的指令即可。在编译时,数据须在以gp为基指针的64KB范围内。
-
$29:($sp)堆栈指针寄存器。
MIPS硬件并不直接支持堆栈,你可以把它用于别的目的,但为了使用别人的程序或让别人使用你的程序, 还是要遵守这个约定的,但这和硬件没有关系。
-
$30:($fp)存放栈帧指针寄存器。
为支持MIPS架构的GNU C编译器保留的,MIPS公司自己的C编译器没有使用,而把这个寄存器当作保存寄存器使用($s8),这节省了调用和返回开销,但增加了代码生成的复杂性。
-
$31:($ra)存放返回地址。
MIPS有个jal(jump-and-link,跳转并链接)指令,在跳转到某个地址时,把下一条指令的 地址放到$ra中,用于支持子程序调用。例如,调用程序把参数放到$a0~$a3,然后使用jal指令跳转到子程序执行;被调用过程完成后,把结果放到$v0,$v1寄存器中,然后使用
jr $ra返回。
2.3 整数乘法硬件单元
实现乘法的操作有多种方式:
-
在标准整数流水线上实现简单乘法操作(例如通过移位即可实现的乘法操作),对于复杂的乘法操作则由软件实现。早期的SPARC处理器就是这样干的。
-
另外一种避免复杂乘法操作的方法就是,在浮点单元中实现整数乘法。Motorola公司曾经昙花一现的88000系列就是这样实现的。但是,这违反了MIPS架构中浮点单元作为可选项存在的定义。
而MIPS架构的CPU具有一个特殊用途的整数乘法单元,独立于主流水线之外。它实现的基本操作是,将两个通用寄存器大小的值相乘,得到一个2倍于寄存器大小的结果,存储到乘法单元中。指令mfhi和mflo分别将结果拷贝到2个特定的通用寄存器中。
因为乘法操作执行比较慢,所以乘法单元硬件实现乘法结果寄存器互锁。后续指令如果过早读取结果的话,CPU会停止执行,直到乘法操作完成。
嵌入式编程小技巧: 能用移位实现的乘除操作,就不要使用`*`和`/`运算。
整数乘法单元同样可以完成除法操作,lo寄存器保存商,hi寄存器保存余数。
乘法操作占用大约4-12个时钟周期,除法操作大约20-80个时钟周期(具体依赖于实现)。有些CPU还有乘法单元流水线(ARM架构就是这样实现的),也就是说,乘法操作可以在每个时钟周期都可以执行,不用再等待上一个操作完成。
MIPS32/64规范还包含一个mul三目乘法指令,将结果的低字节保存到一个通用目的寄存器中。也就是说,这个指令只能计算相乘的结果小于寄存器大小的情况。这个指令还是执行互锁操作,也就是说等到操作完成,才能读取结果;高度优化的软件,仍然会使用分立的指令分别执行乘法操作和读取乘法结果。有些基于MIPS32/64规范的CPU还有累乘操作,连续乘法操作的结果会被相加后保存到lo/hi寄存器中。
乘除操作从不会产生异常:即使除零操作(但是结果是不可预料的)。编译器通常产生额外的指令检查错误并捕捉错误,比如说除零操作。
指令mthi和mtlo,用来拷贝通用目的寄存器的值到内部寄存器中。这对于异常返回时,恢复hi和lo的值是必不可少的,除此之外,可能很少使用。
2.4 加载与存储:寻址方式
MIPS架构的CPU寻址方式只有一种:寄存器索引寻址。任何load和store指令都可以写成下面这样:
lw $1, offset($2)
可以使用任何寄存器作为目的或源寄存器。offset是一个有符号的16位数(所以,范围是−32768~32768);要加载的地址是寄存器$2+offset的值。offset可用于索引结构体成员,数组成员或者函数栈上的变量;再或者配合gp寄存器访问全局静态变量(static和extern)。
汇编器提供了一种直接寻址的写法,但是在编译时,会将其转换成上面的机器指令格式。
更复杂的双寄存器寻址或者可变址索引寻址都必须使用多条指令才能实现。也就是说,我们在编写或者看到的汇编代码中,复杂的寻址指令都是编译器提供的伪指令,在编译阶段,编译器会将其转换成真正的机器指令。
2.5 存储器与寄存器的数据类型
MIPS架构CPU单条指令可以可以存取1-8个字节。
2.5.1 整数数据类型
字节(byte)和半字(halfword)在load时,分为两种情况。带符号扩展指令lb和lh,将值加载到32位寄存器的低有效位,用符号位(字节的话是bit7,半字的话是bit15)填充高有效位。
| 数据类型 | 字节数 | 助记符 |
|---|---|---|
| dword | 8 | ld |
| word | 4 | lw |
| halfword | 2 | lh |
| byte | 1 | lb |
无符号指令lbu和lhu实施0扩展;也就是说,将具体的值加载到32位寄存器的低有效位,将高有效位填充0。
比如:在地址t1处存储着值0xFE(可以解释为-2或者254(无符号)),分别使用有符号指令和无符号指令进行读取:
lb t2, 0(t1)
lbu t3, 0(t1)
那么加载完成后,t2=0xFFFFFFFFE(一个32位的有符号数-2),t3=0x000000FE(252)。
上面是按照32位描述的,对于64位也是适用的,只是操作位数扩大一倍而已。
上述短整数向长整数扩展的细微差异是C语言移植的历史原因造成的,现代C标准有明确的的规则消除可能的歧义。像MIPS这类的机器,不能直接执行8位或16位算术运算,如果涉及到short或char型变量的表达式,就要求编译器插入额外的指令保证运算正确;这应该尽量避免。当你移植代码到MIPS架构的CPU上,涉及到小整数时,要充分考虑哪些变量可以使用int型。
2.5.2 非对齐load和store
MIPS架构的load和store操作必须是对齐的,halfword加载以2字节为边界,32位以4字节为边界。load指令如果访问非对齐地址会产生自陷(trap)。因为CISC指令集架构比如X86架构确实能够处理非对齐load和store,所以,当你移植这上面的软件到MIPS架构上时,可能会遇到问题。也许,你会说,我可以写一个trap处理程序,在其中,模拟非对齐load操作;从而对应用程序隐藏这个硬件细节。除非,非对齐的访问比较少,否则,性能会比较差。
有时候,可能确实需要访问非对齐的数据。MIPS架构确实也提供了一个ulw宏指令,由两个指令组成,比一个个字节的加载,移位,再相加,更高效。还有一个宏指令ulh,使用2个load,一个移位和一个位或操作组合而成,提供非对齐的半字加载操作。
默认,C编译器会正确对齐所有数据,但是也有例外情况(比如,从文件中导入数据或者与其它CPU共享数据时),这时候可能要求能够有效地处理非对齐的整数。所以,有些编译器允许指定数据的类型为非对齐的,从而产生特殊的代码来处理。
2.5.3 内存中的浮点数
从内存中加载浮点数到浮点寄存器中,没有任何限制。对于32位处理器,允许加载单精度值到偶数编号的浮点寄存器中。但是,你也能够使用宏指令l.d加载双精度值。如下所示:
l.d $f2, 24(t1)
编译器会展开为两条指令:
lwc1 $f2, 24(t1)
lwc1 $f3, 28(t1)
在64位机器上,l.d是ldc1机器指令的优选别名。
遵循MIPS/SGI规则的任何C编译器都会将double型浮点数按照8字节对齐。32位处理器没有这个对齐要求,但还是这样做是向后兼容:如果加载一个非8字节对齐的地址处的内容,64位CPU会陷入自陷。
2.6 汇编语言的合成指令
前边我们或多或少提及了一些编译器的伪指令等概念,也可以成为合成指令。因为它是编译器通过多条指令合成的一个伪指令。
为什么需要伪指令呢?
因为MIPS架构只有一种寻址方式。如果我想加载一个立即数到寄存器中,需要先把立即数的地址拷贝到寄存器中,然后再使用load指令从相应的地址处加载立即数,需要两条指令。本身,汇编程序就够晦涩了,现在我只想加载个立即数,还要让我记住两条指令,这太不人道了。所以,伟大的GNU工程中的汇编器提供了合成指令。还是加载立即数,现在,我只需要使用li(等于load immediate)合成指令就可以写了。合成指令的命名是不是也很直接。最后由编译器生成两条机器指令。
此处,又再一次体现了MIPS架构的设计理念:硬件尽量简单,辅以软件实现。编译器提供的辅助有:
-
加载32位立即数:
直接加载立即数。
-
从内存加载数据:
你可以编码一个load,实现从内存中读取变量。汇编器会把变量地址的高字节存储在临时寄存器中,然后使用地址的低字节作为偏移量作为load的操作数进行转译(等效于
load t0, lo_addr(t1),在这儿t1是临时寄存器,存放地址的高字节hi_addr)。当然,这不适用于C函数中定义的变量,因为它们要么是在寄存器中,要么在堆栈上。 -
提供更有效的访问内存变量的方式(gp寄存器):
如果C程序包含大量对static或extern变量的引用,每个load/store操作都需要两条指令,这也是一笔不小的开销。为此,一些编译器就通过实时运行时的gp指针完成这个优化。在编译或者汇编阶段,选择某些变量,把它们聚集到一起组成一块小的区域(不能超过64K)。把中间位置的变量地址存储在gp寄存器(也就是$28)中。后面这需要将gp寄存器作为基址,通过偏移进行访问即可。
通过gp相关的load和store,存取这些变量只需要一条指令即可。相关的优化选项是-G,如果是
-G 0则代表关闭优化。 -
更多类型的分支指令:
合成更多的分支指令。
-
不同形式的指令:
实现单目运算符,比如not和neg等。也提供了双目运算符。真正的机器指令只支持三目运算。
-
隐藏分支延时槽:
汇编器可以优化分支延时槽的使用,比如,把它认为正确的分支指令之前的指令填入分支延时槽中。但是,大部分时候,它没有那么牛逼,只是在分支延时槽中填入了nop操作而已。
如果你不想汇编器改变指令的任何顺序,可以使用汇编伪指令
.set noreorder进行指定;允许的话,就是.set reorder。 -
隐藏加载延时槽:
编译器可以检测load指令前后的语句是否尝试立即使用load结果,如果是,则可能上下移动一下指令。
-
非对齐转换:
非对齐load/store指令(ulh和ulw等)。
-
其它的流水线校正:
一些指令对旧CPU有一些额外的限制(比如说使用乘法单元的指令)。
如果想要查看汇编机器代码,可以借助反汇编工具objdump。
2.7 基本地址空间
MIPS架构具有两种特权模式,用户模式和内核模式。现在,我们讨论MIPS架构对内存空间的分配使用情况。
下图是32位架构下的内存布局:
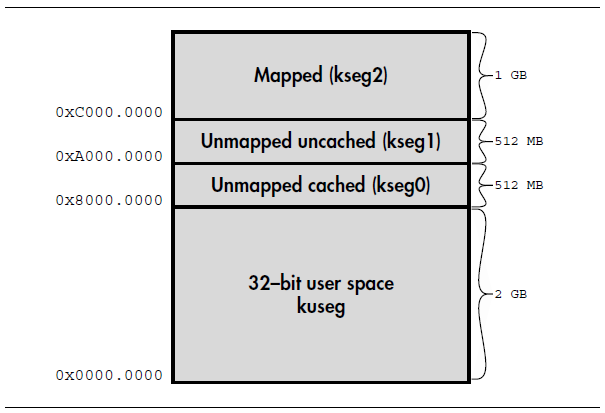
从上图可以看出,将内存空间分为了4部分:
-
kuseg(地址范围0x0000.0000–7FFF.FFFF,低2GB):
用户态使用的地址空间。必须带有MMU内存管理单元的CPU才能使用这段地址空间。对于没有MMU的处理器,该地址空间的使用取决于实现。但是,为了在没有MMU的硬件上,你写的程序可移植,应该避免使用这段区域。
-
kseg0(地址范围0x8000.0000–9FFF.FFFF,512MB):
最高位清零就是物理地址,相当于直接映射物理内存的低512M。这段内存总是通过cache进行访问,所以在使用之前必须配置好Cache。主要用途:如果不使用MMU,则用来保存程序和数据;如果使用MMU,则存放OS内核程序。
-
kseg1(地址范围0xA000.0000–BFFF.FFFF,512MB):
前面的3位清零就是物理地址。也被映射到物理地址的低512M。但是,访问不通过Cache。
系统重启时,唯一能访问的地址空间。复位后的启动入口点就位于这段地址空间(0xBFC00000)。而物理地址的启动入口点就在地址0x1FC00000。因此,初始化启动程序ROM一般使用这个区域,还有许多作为I/O寄存器使用。
-
kseg2(地址范围0xC000.0000–FFFF.FFFF,1GB):
内核态可以访问的地址空间,前提是使用MMU。除非是开发操作系统,否则一般不会使用这个空间。有时候,会把这段地址空间分为两部分,分别称为
kseg2和kseg3。kseg2就保留给管理模式使用,如果使用了管理模式的话。
2.7.1 简单系统的物理寻址
对于非常简单的系统,大部分时候物理内存不会超过512MB。所以只需使用kseg0和kseg1的地址空间即可。但是,如果实在需要,可以将转换项存放于内存管理单元的TLB中,从而访问更高地址的内存。另外,如果是64位CPU,还可以使用额外的空间访问。
2.7.2 内核与用户特权级别
在内核特权下(CPU启动)可以做任何事情。在用户模式,访问高于2GB以上的地址是非法的,会产生自陷(trap)。如果CPU有MMU,意味着,用户模式下的地址必须经过MMU的转译才能访问物理内存,这样可以阻止用户模式下的程序非法访问内核模式的地址空间。这也意味着,如果MIPS架构的CPU上运行的是一个没有内存映射的OS内核,则用户特权级是多余的。
另外,在用户模式下,一些指令,尤其是OS需要的CPU控制指令是非法的。
改变内核/用户特权模式,不会改变任何行为,只是意味着某些功能在用户模式被禁止。在内核态,CPU能够访问低地址空间,就像它们处于用户模式一样,也使用相同的方式进行转换。
另外还需要注意的是,虽然看上去内核模式专门为操作系统设计的;用户模式处理日常的工作。然而,事实并非如此。很多简单的系统(包括许多实时操作系统)一直处于内核模式运行。
2.7.3 64位地址映射
MIPS架构的地址总是通过一个寄存器的值加上16位的偏移计算得到。而在64位MIPS架构CPU中,寄存器的位数是64位,所以可以访问的地址空间是2^64,这样巨大的地址空间可以任由我们分配,如下图所示。
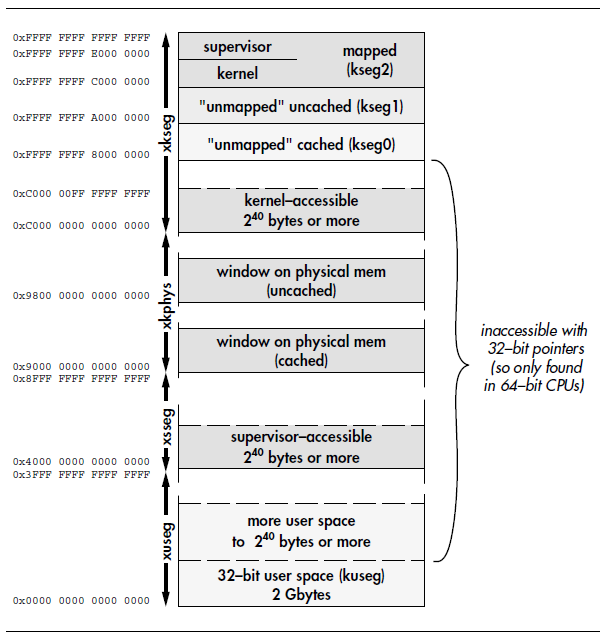
在上图中,我们可以看出,64位内存地址的扩展部分都位于32位内存地址的中间,这是一个很奇怪的实现技巧。我们知道,MIPS架构在短整数向长整数扩展时,使用了带符号位的扩展方式。在64位CPU上模拟32位指令集时,寄存器的低32位保存实际的地址值,高32位根据bit31位作为符号位进行扩展,这样32位的程序实际访问的是64位程序空间的最低2GB和最高2GB程序空间。这样,扩展的内存映射把最低空间和最高空间用作和32位系统一样的地址空间,扩展的空间就位于这中间了。
事实上,这么大的地址空间大部分时候根本没有意义,除非你正在实现一个虚拟内存操作系统,要不然基本用不上;因此,许多MIPS64用户还是把指针定义为32位长度。这些未映射的地址空间可以用来突破kseg0和kseg1的512MB的限制,但是,这完全可以通过内存管理单元(TLB)实现。
2.8 流水线可见性
关于流水线的可见性,在之前的文章中已经涉及过,比如分支延迟和load延迟。任何一个带有流水线的CPU,如果有指令不能满足一个时钟周期执行完的要求的话,都会面临时序延迟的问题。如果架构设计者隐藏这些时序延迟问题,那么编程模型相对于编程人员就会变得相对容易,但是硬件实现就会复杂。而如果把时序延迟问题暴露给编程人员,让他们通过软件规避这些问题,硬件实现容易了,但是软件设计就会变得复杂。所以,这是一个平衡和选择的问题。
我们知道,MIPS架构的设计理念是:硬件尽量简单,辅以软件实现。所以,MIPS架构把一些流水线的时序延迟问题暴露给编程人员或者编译器去优化实现。下面,我们总结一下这些时序延迟问题:
-
分支延迟:
所有的MIPS架构CPU,紧跟在分支指令后面的指令不论分支指令是否发生跳转都会执行。所以,编程者或者编译器可以选择一条合适的指令放到分支指令的后面,提高CPU的执行效率。最差的情况也要填充一个nop指令。编译器默认情况下,就是填充nop指令。
-
加载(load)延迟:
优化编译器和编程者应该意识到一次load操作所花费的时间,不要尝试立即使用loading中的数据。load延迟会影响系统性能,硬件设计者尽量保证为load之后的下一条指令准备好数据。
-
浮点单元(协处理器1)的问题:
浮点运算花费多个时钟周期,典型的MIPS架构FPU硬件有一个某种程度上相对独立的流水线单元。MIPS硬件必须对用户隐藏这些FPU流水线。FP运算被允许和后面的指令并行计算,增加CPU的执行效率。如果在计算没有完成的时候读取结果寄存器,CPU应该停止执行等待计算完成。真正深度优化的编译器拥有指令重复率表和每个目标CPU延迟表,但是,我们大部分时候不想依赖这些。
-
CPU控制指令的问题:
这个是需要慎重对待的东西。当你改变CP0中相应位的时候,潜在地可能正在影响流水线上的各个阶段。
MIPS32/64规范在第二版后,对这方面进行了改善。与CP0的交互可以分为两部分:一种情况是先前对CP0的操作可能会影响后一条指令的取值,这也是最麻烦的,称为指令遇险;另一种情况就是执行遇险。MIPS架构提供了两种屏障(barrier)指令规避这些情况的发生:一种是用于执行遇险;另外的是加强的分支指令,可以保障在发生指令遇险时的安全。
在第二版之前,没有提供相关的屏障指令。需要编程者阅读相关的CPU手册,发现应该添加几条填充指令避免这些副作用的发生。
这部分的内容跟ARM的内存无序相关问题类似。ARM的解决手段要么锁总线,要么添加内存屏障指令`rmb()`。